7 key principles of context engineering
Explore key principles of context engineering and how they establish long-term success for platform engineering and agentic systems.

Context engineering has become a staple of platform engineering. It’s how platform engineers give both human developers and AI agents the information and situational awareness they need to act safely and successfully.
In this post, we’ll explore some key principles of context engineering, how they shape platform engineering and agentic systems, and how they establish long-term agentic success. This list isn’t all-encompassing — different organizations have different needs, it’s not one size fits all — but experts largely agree the principles covered here are essential.
What are key principles of effective context engineering?
Many principles make context engineering work, and each principle is individually important. However, the way these principles impact and improve one another are what makes context engineering effective, as they work together to address the needs of both human developers and AI agents.
1. Provide relevant, high-quality data
You can’t build a proper foundation for your team with just raw data. You need to curate and structure this data to help both your human developers and AI agents make sense of relationships, dependencies, and other important conditions.
Your first goal should be to create a context lake. This context lake is the keeper for your engineering metadata, domain and organizational knowledge, operational status, and more. It provides a clear, machine-readable way to structure and share data with both humans and AI in your organization.
The context lake cuts down on the cognitive load human developers need to complete tasks, and simultaneously gives AI agents the information they need to understand your SDLC and navigate complex queries.
A good first step toward building your context lake is to build a software catalog or knowledge graph that structures data with context about relationships and dependencies to set your team up for success. Then, create actions for your agents and humans to execute workflows, and make scorecards to ensure your actions are performed safely and effectively.
The context lake you create and the context windows you provide to your AI agents directly shape their output and performance quality. As a result, token budget management and retrieval strategy optimization are critical. We recommend the following tactics for improving agent output:
- Prioritizing what information is included in an agent’s context window
- Adjusting how large of a window agents have
- What context they can access at runtime
In his article on context engineering, Dr. Adnan Masood notes: “LLMs will faithfully use whatever you provide in context, so you must curate it well.” AI agents will perform tasks based on the context they’re given, so you have to give agents relevant data that makes it possible for them to succeed.
2. Ensure data is dynamic and continuously updated
The success of your developer team is tied directly to the information they can access. If your team — again, human or AI — is working with outdated or contradictory documentation, results will vary. For human developers, that could mean extra time lost having to rewrite and fix code. For AI agents, it could mean their code turns out to be unreliable.
Context validation and context versioning are key. Continuously curate and maintain knowledge bases and other relevant documents so your human developers can work more efficiently. Similarly, make sure the context you provide to your AI agents meets current organizational knowledge, so your agents can return accurate, up-to-date outputs.

3. Incorporate both structured and unstructured knowledge into the context lake
Combining structured knowledge from within your organization, like engineering metadata, with unstructured knowledge, like operational stats from the various tools and databases your team uses in their software development life cycle (SDLC), is a key component of context engineering.
For human developers, bottlenecks in the SDLC pop up quickly when the tools and information they need aren’t all in one place. Some devs have to wait up to three days for someone else to give them approval to use external tools they need to get the job done.
In the same vein, an AI agent can’t complete tasks related to critical information stored in external tools it can’t access. It may even take destructive actions unexpectedly in its attempts to rectify its goal with the information it does have access to. These cross-system relationships impact the agility, security, and efficiency of your organization’s SDLC, so make sure your teams are properly equipped with the tools and information they need.
4. Centralize data into one source of truth
Once you’ve identified the data you need, creating one source of truth is a must. Having relevant data in a single place is critical when 72% of CEOs predict they and their employees will have agents reporting to them within five years. Your source of truth needs to aggregate real-time data, especially as AI scales, to avoid dragging AI down to human speeds. Human developers access this data through an internal developer portal (IDP), where AI agents reach it through a Model Context Protocol (MCP) server.
In addition to the organizational benefits, having a single source of truth provides oversight and governance opportunities:
- Humans can more accurately read and audit AI-led actions
- Humans can validate what actions agents took and verify the quality of the output/results
- More experienced developers or policy-driven agents can help other agents make better choices on repeat tasks
- Managers can see which models perform best in their specific environments, and ensure older or weaker models they need to deprecate
5. Give agents a clear scope for each task
AI agents are most effective when the context they’re given is focused specifically on the task they’re told to do. The quality of an agent’s output can actually degrade if the agent is given too much or too little data to complete the task.
Creating dedicated agents for different tasks, applying role-based access control to each agent based on the tasks they’re going to perform, and limiting the agent’s scope to the context they need to efficiently perform their tasks will ensure successful returns.
The specific context each agent needs will vary and can range beyond the user’s prompt. It may include the history of the conversation with the user, details specific to that organization, or even organizational vocabulary (e.g., defining what constitutes an incident, or clarifying that in a particular work environment, “service” could mean “microservice”). Domain-integrated context engineering takes this one step further by providing organization-specific workflows, ownership models, and golden paths that are unique to your specific engineering environments and SDLC.
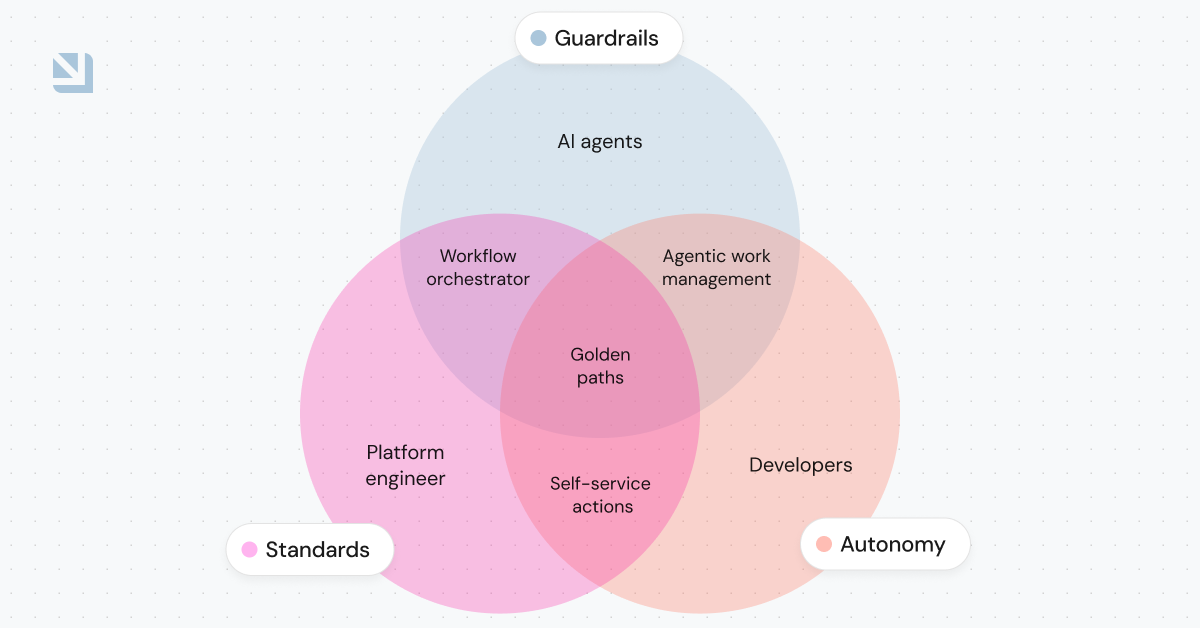
6. Share context between agents for multi-step processes
When a task involves multiple AI agents, human-in-the-loop approvals, or multiple workflow steps, memory management becomes a challenge. The previous steps in the process and the output of those steps need to be included in the context provided to subsequent developers or agents.
For workflows that involve multiple steps, later actions assigned to an AI agent may not align with the previous actions taken by another agent if it lacks the context of that agent’s previous actions. In the case of a process with multiple agents — or work split between human developers and agents — the output from agents and developers may be incompatible if the agents and developers don’t have access to the same context. For example, a release management agent may close a task prematurely if it wrongly believes a previous agent has already merged code into production. In this case, the code will sit unmerged, but the task appears complete in Jira.
How you solve issues of memory management will ultimately depend on your organization’s needs and the tools you have to work with, but sharing context across steps is necessary to successfully complete multi-step processes like these.
7. Build security and human oversight into every agentic workflow
While AI agents can provide real opportunities to streamline an organization’s SDLC and accelerate software production, it’s vital to include human oversight and documentation of changes made by AI in case anything goes wrong. Two must-haves include:
- Human-in-the-loop context: At some point in the process, a human developer needs to be involved to keep AI agents on the right path. Additionally, agents that do work after that human involvement need to have the context the human developer provides.
- Audit trails: It’s important to know what context drives each of AI’s decisions. Context logs, or logs about what context was provided to each agent and each decision, make it possible for humans to validate and debug work an AI agent does.
These safeguards ensure your SDLC moves forward within guardrails, bolstering your team’s efficiency and agility.
Use Port to perfect your context engineering
When your organization uses Port, these principles are built into your SDLC by default. As an industry leader in agentic platform engineering, we apply these principles to our IDP (as we evolve into a true Agentic Engineering Platform) and our MCP server, which combine to give your human developers and AI agents the tools they need to succeed.
{{cta_3}}


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone




