Ready to start?
AI agents are only as effective as the context they can access and the guardrails you have in place to keep them in check. Agents that understand the unique landscape of your software development lifecycle perform better: they write better code, they take better actions, and they make safer decisions.
As teams are racing to adopt agentic workflows, questions like these keep coming up: where does all that context live? How do they know when to start, stop, or continue work?
The answer is a new concept: the context lake.
With access to structured knowledge via a context lake, AI can safely take approved actions, use unstructured data to “reason” through problems, and check engineering metadata to make decisions responsibly. This makes AI outcomes more deterministic.
On top of access to your business, engineering, and operational context, AI agents also need to be contained and controlled. They need strict, clear guidelines for behavior in order to avoid taking destructive actions, like accidentally deleting important repositories.
We’ll explain what a context lake is, how it relates to your business and engineering metadata, and how it makes AI agents more reliable, scalable, and secure.
What is a context lake?
A context lake is an aggregated, structured repository where all the information an AI agent needs to operate is stored, correlated, and governed. Each context lake is as unique as the organization that built it; it should reflect your software development lifecycle (SDLC) in real time.
Think of it as the next evolution of the data lake. Where a data lake holds raw data for analytics or business intelligence, a context lake holds actionable, domain-integrated knowledge that both humans and agents can tap into to complete tasks.
Within your infrastructure architecture, the context lake is a layer that comprises raw data relating to:
- Domain knowledge: Your APIs, services, dependencies, and architectural blueprints. For example, this could be the GitHub repository for an existing service, including its files, structure, and README.
- Operational state: Real-time metrics, logs, incidents, and changes in progress. These could be your PagerDuty service as well as the Kubernetes cluster on which the service is deployed, and its current state.
- Engineering metadata: Ownership, policies, access controls, quality signals, and observability data. Simply put, this could be the service’s owning team and its members, as well as run history and recent incidents.
- Actions and tools: Available self-service actions, automated workflows, and notification criteria that you’ve built into your platform, usually an internal developer portal. AI agents can see what is possible for them to do on their own, which gives them autonomy while hiding unwanted actions.

When you pair the context lake with an MCP server, you can expose these tools to agents so they can take informed, independent actions while complying with your precise organizational standards. The MCP server is the interface between agents and your context lake, in the same way that a UI works for humans.
Why engineering metadata is key to context lake success
Engineering metadata describes the systems, services, and resources in your software ecosystem and gives you the current state of each. The real-time nature of this data is essential for agents to be true members of your team.
Engineering metadata is what makes your development environment unique. For example, at some companies, DevOps owns Datadog and in others, SREs own it. It can make sense for either team to own Datadog, but AI needs to know what you’ve decided in order to communicate with the proper teams throughout the SDLC.
In contrast to your domain knowledge — which comprises data about your integrated systems and any scorecards, blueprints, and software catalogs you have — engineering metadata gives your AI agents a solid, contextual foundation for how your teams operate in safe, efficient software development. Onboarding agents in this way, as you would junior devs or new employees, is what encourages deterministic behavior and reliable outputs.
With access to your business context, AI agents can perform discovery actions, enforce policies, and collaborate with other agents. You can ask AI assistants familiar questions like:
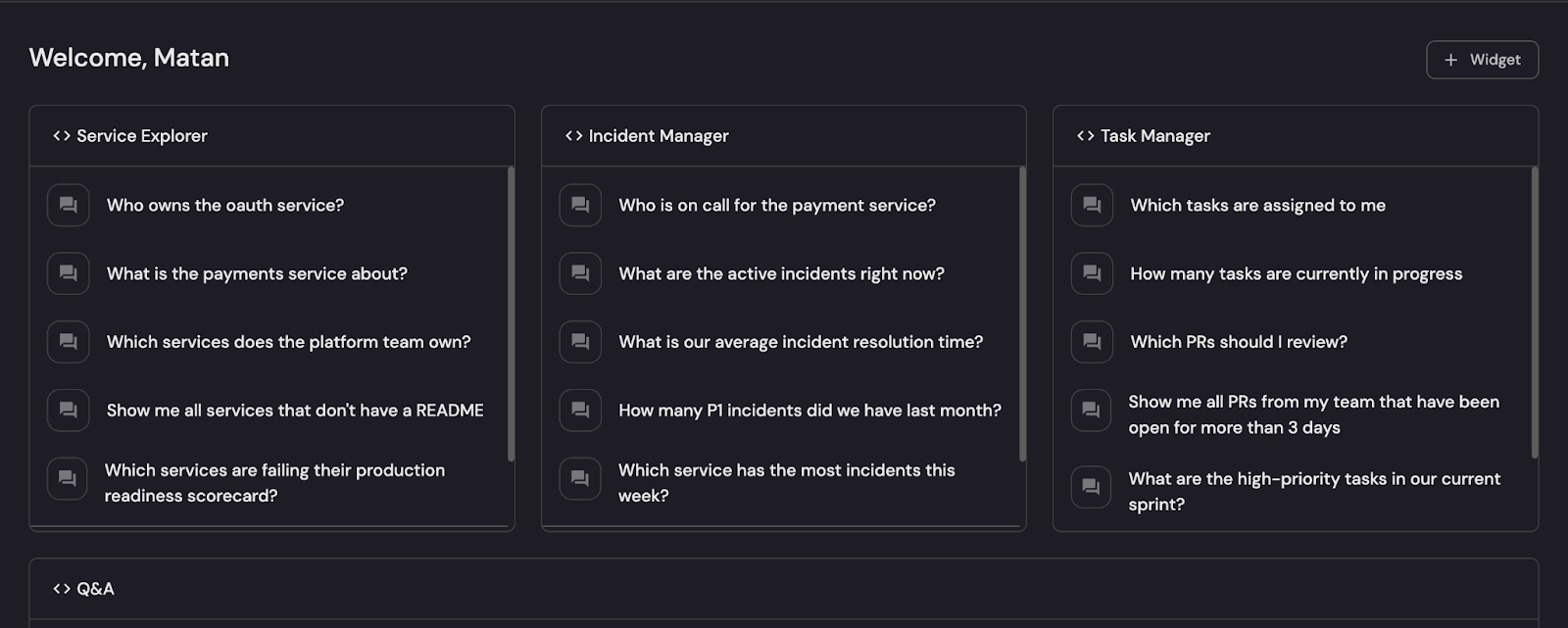
But consider how handy this becomes when you start using agents across your SDLC.
How a context lake benefits teams
If you give an agent only raw data — that is, data that lacks the structure of your SDLC or business metadata — you’ll get unpredictable results. Agents can hallucinate, duplicate work, or make unsafe changes if they aren’t properly governed. This contributes to agentic chaos, which is really just a robust and exponentially worse version of engineering chaos.
A fully domain-integrated, governed AI agent isn’t just an agent that can answer your questions or write boilerplate. It can handle numerous tasks independently, monitor its own compliance with policies, and help humans maintain governance over other agents in a truly collaborative working environment.
There are three main ways a context lake helps improve AI, which we’ll cover below.
1. Providing AI agents with higher-quality inputs
Agents given unstructured, unlabeled data struggle to generalize. If they can’t form patterns and recognize them throughout your SDLC, their output won’t be reliable.
You can make agents more predictable by providing consistent, structured examples of the data they should use and the outputs they should model their responses after. Metadata like ownership, service type, and compliance tags turn “just another API spec” into reusable learning inputs (or prompts) that you can duplicate and customize for a wide variety of agent types, such as a Product Manager agent or a Tech Lead agent.
When operational data is enriched with engineering metadata like dependencies, tags, and risk levels, it becomes structured onboarding material. To put it simply, metadata tells the agent what it can and cannot do.
Instead of asking, “What’s this API?” an agent can ask, “What’s this PCI-compliant API owned by Team A with three downstream dependencies?” That context dramatically improves performance and helps build repeatable, reusable outputs.
2. Governing AI agents responsibly
You can also provide AI agents with governance frameworks and guardrails to follow. Proper AI governance is largely similar to the concept of “golden paths” in platform engineering; they’re hard-coded workflows and pipelines constructed within your platform that ensure standards are met with every deployment.
Think of golden paths like the Yellow Brick Road, or like train tracks: they provide clear instructions for completing tasks successfully, to both humans and agents. Without these guardrails, agents risk breaking SLAs or ignoring security policies in favor of acting quickly.
Destructive actions are one of the biggest fears around AI agents. A context lake prevents these from occurring by embedding policies and controls directly into the metadata layer, making new workflows possible:
- A deployment agent checks metadata before rolling out changes.
- A cost-optimization agent only touches services with a “safe-to-scale” tag.
- A support agent only accesses logs with the proper PII classification.
The context lake enforces your standards before agents take any action.
3. Orchestrating agentic workflows at scale
Implementing an orchestration layer like an agentic engineering platform helps make agent onboarding scalable and structured. Just the same way HR teams own the work of introducing new employees to the company, the orchestration layer organizes information and provides agents with an onboarding structure that can serve many agents (and humans) at once.
It can also help them coordinate actions and collaborate. Multiple AI agents are sometimes referred to as an “intelligent swarm,” which can chain single-point actions and agents into fully autonomous workflows. Imagine:
- An incident-response agent detects a failed service.
- It queries the context lake, finds the owner, and opens a ticket.
- A remediation agent picks up the ticket and deploys a patch.
- A compliance agent logs the change for audit.
With a central source of truth like a context lake, you can make full, production-ready use of your AI agents just like this. Agent swarms make it possible to create self-healing code pipelines and incident triage workflows that safely leave humans undisturbed.
As teams move from using discrete, single agents to coordinated multi-agent systems, orchestration becomes critical. A context lake provides the shared source of truth agents need to collaborate, with humans and each other, effectively.
The road ahead: Agentic engineering powered by context
Context lakes are still an emerging concept, but the pattern is clear: as agents take on more responsibility, the need for domain-integrated context engineering only grows.
Just as data lakes transformed analytics, context lakes will transform AI-powered software engineering. They will allow teams to train better agents, enforce stronger governance, and orchestrate complex workflows at scale — all while improving developer experience.
If you’re exploring AI agents in your organization, start by asking: where does your context live today, and how are you enriching it with metadata? The future of safe, effective agent orchestration depends on the answer.
{{cta_1}}


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
LIVE WEBINAR, Aug 18, 2026:
Context-aware Vibe Coding for Platform Engineering
Move fast while staying in control
Build governed agentic workflows on one central platform.
To see it in action, check out this video on how you can create a workflow that generates Terraform using Port, or just have a quick look at our public demo.
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone