The Agentic SDLC: The Software Lifecycle, Rebuilt Around Agents
The agentic SDLC is the software development lifecycle rebuilt around AI agents.


Getting one AI agent to pick up a ticket, write the code, run the tests, and open a pull request is a solved problem. And tickets are only the start. The same agents can generate and run tests, push a release behind a flag, watch production, and triage an incident at 3 a.m.
The agentic SDLC is the software development lifecycle rebuilt around AI agents. The agents lead the work: planning, coding, testing, reviewing, shipping, operating in production, and keeping standards. Engineers set the intent, review across stages, and point the agents at the goal. The engineer's job changes with it: less time writing code, and more time deciding what good looks like and checking that the agents got there.
That single-agent flow, one agent taking a task from ticket to PR, is already real, and you can demo it today. The harder part is what happens when agents run at scale across a real org, and that is what decides whether your agentic SDLC actually helps or quietly turns into a mess.
If you take three things from this guide, take these:
What it is: agents lead the whole lifecycle. The engineer's job moves to setting intent, reviewing, and governing.
Where it gets hard: one agent is easy, dozens across a real org is not. That gap is agentic chaos.
What actually wins: not the cleverest agent (that's becoming a commodity) but the control plane underneath: context, human in the loop, guardrails,visibility and ROI.
In this guide, we'll cover:
- What's the difference between an assistant and an agent?
- How does the traditional SDLC compare to the agentic SDLC?
- What do agents actually do at each stage?
- What does it take to build an agentic SDLC at scale?
- What's platform engineering's role in the agentic SDLC?
- What's the software engineer's role in the agentic SDLC?
- Common questions about the agentic SDLC
The difference between an assistant and an agent is who's driving
The simplest way to tell them apart is to ask who's driving. With an assistant, you are. With an agent, it is.
With an assistant, you stay in the driver's seat the whole time. You type, it suggests, you accept or reject. The code and the judgment both still come from you. An agent works differently. You hand it a goal, like fix this bug, build this endpoint, or migrate this dependency, and it works toward that goal across many steps without you directing each one. It reads the relevant code, makes a change, runs the tests, reads the failures, fixes its own work, and comes back with a result. You set the intent at the start and judge the result at the end. The part in the middle, which used to be most of the job, is now the agent's.
Traditional SDLC vs. agentic SDLC, stage by stage
It helps to see the two side by side, because the agentic SDLC doesn't throw out the lifecycle you already run. You still plan, build, test, review, release, and operate. What changes is the work inside each stage, and one column deserves more of your attention than the rest: what the engineering team is left holding. Read the table by that column and you'll see where the job actually moves.
Keep standards sits across the bottom on purpose, because it isn't a stage you visit once. Security, compliance, code quality, and production readiness used to be a gate at the end. When agents act hundreds of times a day, a gate at the end is too late. The check has to run on every action, or it may as well not run at all.
The metrics move in both directions, and it's worth being honest about that. A well-governed agentic SDLC improves both the DORA numbers and the SPACE ones. An ungoverned one makes change failure rate and MTTR worse, because nothing is there to catch a bad change before it spreads.
The first four are the DORA metrics; the last three map to SPACE.
What do agents actually do at each stage?
The table shows who's driving each stage. Here is what that looks like in practice, with one common example per phase.
Plan
A ticket comes in: users report slow checkout. A planning agent pulls the related services from your context lake, the live, connected model of your engineering world: your services, who owns them, what depends on what, what shipped recently, and what's been tried before. It's what lets an agent reason about your systems instead of guessing. The agent sees that checkout calls a payments service and a fraud service, reads the recent latency data, and drafts a tech spec that names the likely culprit and the files involved. The engineer reads a real plan instead of a one-line ticket. Turning a vague request into scoped work like this is the front half of autonomous ticket resolution.
Build
Once the plan is approved, a coding agent like Claude Code or Cursor opens the repo, adds a cache to the fraud-check call, updates the config, and opens a pull request. From here nothing is new. The PR runs through the same CI/CD pipeline your DevOps team already built. That pipeline is the foundation the agentic SDLC rides on, not something the agent reinvents. The agent's job is to produce a clean, reviewable change that your existing pipeline can take the rest of the way.
Test
The agent writes tests for the new cache path, runs the suite, and hits a failure: under load, the cache returns stale fraud scores. It reads the stack trace, reproduces the case, adds a TTL, and reruns until everything passes. Model output is non-deterministic, so this loop (write, run, read the failure, fix) is what separates an agent that works from one that confidently ships a bug.
Review
A review agent reads the diff against your standards before a human opens it. It runs the change through your production-readiness scorecard and flags what's missing: the new cache exports no metric, has no owner in the context lake, and hardcodes the TTL instead of making it configurable. It leaves those as comments. Now the human reviewer can spend their attention on the one call that actually needs judgment, whether caching fraud scores is an acceptable risk, instead of catching a missing metric by eye.
Release
Release is where risk management matters most, because a release is where a bad change reaches real users. A release agent first gathers the context for the change: who owns the service, the test results, where it's going, and the recent deploy history. It scores the risk from that, then decides whether to hold the release or let it through. When it lets one through, it doesn't just push to production. It posts to Slack so the team can pick the rollout strategy, canary, feature flag, or blue-green, then ships to a small slice of traffic and watches error rates and latency through the workflow orchestrator. It ramps up only if the numbers hold, and rolls back on its own if they don't. The payoff a manager cares about is concrete: time saved, money saved, and how many risky releases never reached production.
Operate
Two weeks later, a Datadog alert fires on the fraud service. An operations agent ties it to the last deploy, points at the cache as the change, drafts a config rollback, and pages the on-call through PagerDuty with a one-line cause and a fix attached. That is what self-healing incidents look like in practice. The human approves a fix instead of building one from scratch at 3 a.m.
Each of these works on its own today. The hard part is the wiring between them, and that's where most agentic SDLCs break.
What does it take to build an agentic SDLC at scale?
As an industry, we've moved through three phases, and the first one is nearly gone:
- Phase 1, manual engineering. People wrote every line, and tools only formatted and linted. Almost no one works this way anymore.
- Phase 2, AI-assisted engineering. Copilots and chat tools suggest while people still drive, so individual developers get faster. Most teams are here today.
- Phase 3, AI-led engineering. Agents do the work across the lifecycle while people set intent and govern. A few teams are here in pockets, but almost none org-wide.
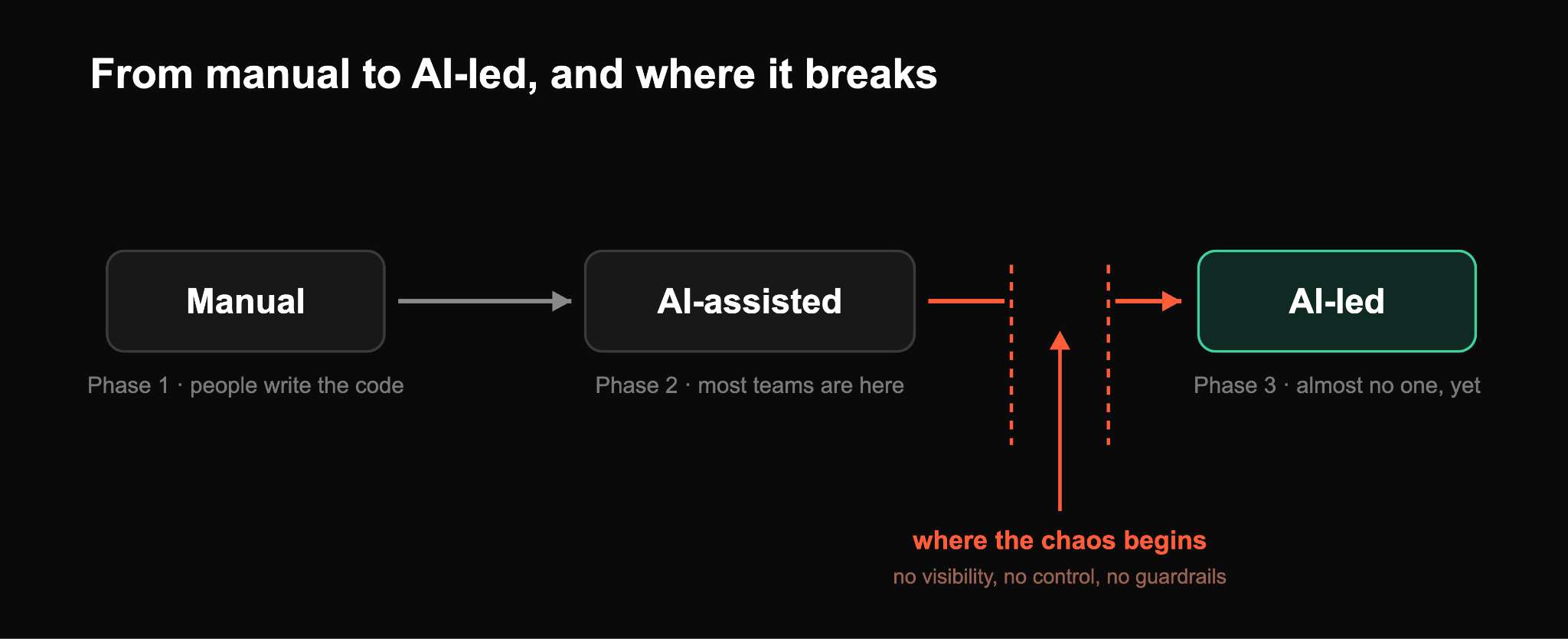
The gap between Phase 2 and Phase 3 is the hard part, and it's worth being clear about why. In Phase 2, one developer runs one agent on their own laptop, and if it goes wrong the damage stops at their machine. In Phase 3, agents act across shared systems, with real credentials, on production, dozens of them at a time. The blast radius is the whole org.
That gap is where most teams get stuck. You end up with what we call agentic chaos.
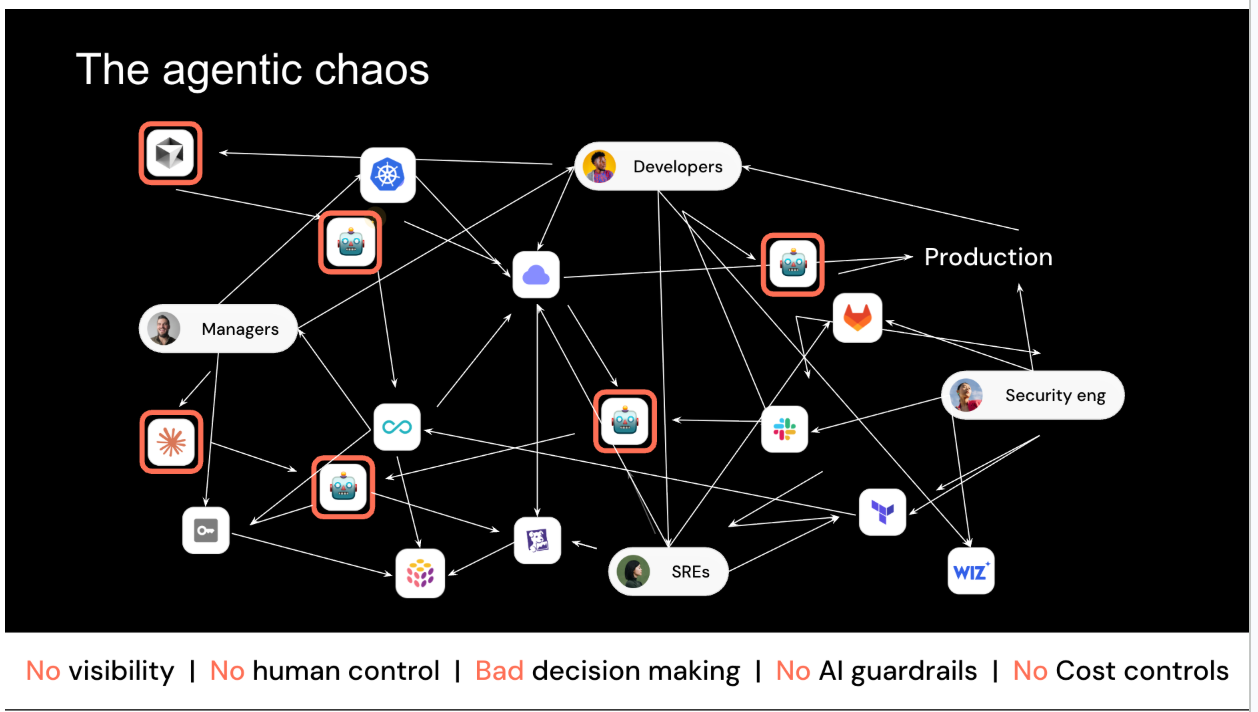
Organizations wire agents to everything they can reach through MCP. The context comes back scattered and messy: stale ownership, half the picture, sources that disagree. The agent reasons over that and reaches a confident wrong conclusion, burning tokens the whole time as it hunts for data and stitches it together. Since no one scoped what it can touch, it acts on that conclusion: hits the wrong service, runs a destructive operation, ships a change no one approved, with no one in the loop to stop it. Then something breaks, and nobody can trace which agent did it, on whose credentials, or why. And right about then, leadership asks the other question: what is all this AI actually doing for the business? "We spent a lot and we're not sure what we got" is a rough place to be standing. Multiply that by every team running its own agents, and no one can see across it anymore.
What does it take to eliminate the chaos?
Start with the agents, and then everything around them. The agent itself is the small box: a few model calls, a prompt, and some tool definitions you can wire up in minutes. The seven blocks around it are what it actually takes to run an agentic SDLC in production, and each one is work nobody plans for when they build the demo.
- Integrations. Agents have to reach your real systems: CI/CD, cloud, incident tools, repos, secret managers. Without a central layer, every team wires its own credentials, so the same kind of agent sees a different slice of the org depending on whose token it ran with, and one breaking GitLab API change has six teams debugging the same failure separately. MCP gives agents a standard way to call a tool, but it doesn't manage the credentials, scope the data that comes back, or handle the API changing underneath it.
- Context lake. An agent is only as good as the context it can reach, and it needs two kinds. There's live runtime context, like what a service runs on, who owns it, and what shipped recently. And there are decision traces, the record of what's been tried before and why. Without traces, an agent reopens a PR that another agent already got rejected last week. A static agents.md goes stale the moment ownership changes hands, which is why this belongs in a live context lake rather than a file.
- Agent registry. You now have several times more agents than employees, created daily across Cursor, Claude Code, n8n, and more, with overlapping jobs and dependencies nobody can see. Before agents can be shared, governed, or audited, you have to know they exist, and every one should start from a template with an owner, the tools it uses, the services it touches, and a lifecycle state. That's what makes an agent governable from day one, instead of something you find running in production six months later with expired tokens and no one to call.
- Measurement. Whether an agent is working depends on who's asking. An SRE wants observability: what did it do, and where did the chain break. An ML engineer wants evals: is it better or worse after a prompt or model change. And leadership wants the money answer: what did it cost, and what did it return. Cost is trackable if you attribute token and compute spend per agent and per team, but spend on its own is only half the story. The ROI question gets answered only when you tie that spend to outcomes: tickets resolved, hours saved, incidents prevented. Get that wrong and you can show a big bill with nothing to set against it.
- Human-in-the-loop. Between fully manual and fully autonomous runs a spectrum, and where an agent sits depends on the action, the environment, and the risk. A deploy agent might run free in staging but need approval in production, or run on its own at noon but check with a human at 3 a.m. Hard-coded Slack approvals don't survive 100 agents across 20 teams, so you need checkpoints set in one place and a shared view where people can watch agents work and step in.
- Governance. When a person needs production access, there's a scoped, logged process. An agent built locally just inherits whatever credentials its creator wired in, usually with no review. Governance means rules set in one place (roll back only on a high-severity incident, production deploys always need approval), enforcement you can trigger on the spot (disable a compromised tool across every agent at once), an audit trail that shows which agent did what with whose credentials, and cost limits so an agent stuck in a retry loop doesn't burn tokens until the invoice shows the damage. Scoped access and policy is the spine of all of it.
- Orchestration. A real workflow is rarely one agent. It's a chain of agents, tools, and people handing off to each other, and the trouble lives in the handoffs: how work gets routed, what happens when a step fails, and who owns the result. Picture an incident workflow where a triage agent decides the cause, then hands off to an agent that rolls back the deploy. If the triage agent is wrong, the rollback fixes nothing and the real issue keeps burning, and figuring out which handoff went wrong is its own investigation. A CI/CD pipeline is predictable because every step has a fixed input and output. Agent chains don't, so a single prompt change in one agent can quietly change what the next one receives and break the whole chain.
No one of these blocks is the fix on its own. The chaos clears only when all seven live in one place and are governed together, so an agent gets the right context, only the access it should have, a human checkpoint where the stakes are high, and a record of everything it did. That single place is what an agentic engineering platform is: the control plane you build your agentic SDLC on, so agents act across the lifecycle under control instead of in the dark. The coding agent itself, by contrast, is becoming a commodity. Within a year the gap between the top models will be a footnote, and the platform underneath them is where the real work is.
What's platform engineering's role in the agentic SDLC?
Platform engineering's job in the agentic SDLC is to build the control plane agents run on, and to make it good enough that developers choose it instead of going around it.
The deal has always been the same: make engineers self-sufficient without giving up standards. Self-service plus standards gave developers velocity and gave the platform team control. AI broke that balance. Developers became builders of agentic workflows (SRE agents, release agents, skills), and they didn't wait for permission, because Cursor and Claude Code run locally and the pressure to ship is real. What you get is agent sprawl: agents taking destructive actions with no audit trail, no respect for PII, and no scoped credentials, because nobody built them to the company's standards in the first place.
A platform team has three options, and only one of them works. You can do nothing, and the sprawl wins, with no visibility and no way to step in when something breaks. You can mandate that all agent work flows through you, and get a revolt and a slower org, because the tools are already in developers' hands. Or you can make the platform the place developers actually want to build, by clearing the walls they hit every time: scattered data, tangled integrations, missing approval gates, and far too much access to critical systems.
That turns platform engineering into a product job. You learn what developers are trying to build, then take away the hardest parts. Give them discovery, so they know what data, integrations, and actions exist before they start. Give them early wins with starter templates and pre-built skills to fork. And give them a registry where good work piles up the way it does in open source, so the next team builds on the last one instead of starting over. Done well, governance isn't the thing slowing developers down. It's the thing that lets them move fast without getting hurt.
What's the software engineer's role in the agentic SDLC?
In the agentic SDLC, your job as a software engineer changes more than it shrinks. You spend less time writing code and more time setting intent, reviewing what agents produce, and owning the calls agents shouldn't make on their own.
The day-to-day loop is different. It used to be: pick up a ticket, gather context, write the code, fix it until it works. Now it's closer to: work out the best way to solve the problem, frame it so an agent can run at it, and judge what comes back. The skills that matter move up a level. Choosing a solution that's reusable rather than one-off, so the next agent and the next team build on it instead of around it. Writing intent precisely enough that an agent doesn't wander off. And reviewing from above the code, not line by line, but asking whether the design holds up at scale, fits the architecture, and is actually the right approach rather than just something that passed the tests.
This raises your leverage rather than lowering it. One engineer who can direct and review a fleet of agents ships what a whole team used to, and that makes the things only a person brings worth more: taste, architectural judgment, and the call on what counts as acceptable risk. The worry that AI will replace developers misses where the hard parts always were. They were never in the typing, and the typing is the part that's going away.
The short version: agents can already do the work at every stage of the lifecycle, so the teams that win won't be the ones with the cleverest agent. They'll be the ones who built the place for agents to run, with shared context, scoped access, human checkpoints, and a record of everything. Get that right and the agentic SDLC is the most leverage your engineering org has had in years. Skip it and you get chaos that's expensive to clean up later.
See how Port turns this into infrastructure you can build on. Book a demo.
FAQ
What is the agentic SDLC?
The agentic SDLC is a software development lifecycle where AI agents do substantial parts of the work, including planning, coding, testing, reviewing, deploying, operating, and keeping standards, by pursuing a goal across many steps on their own, while engineers set the intent and approve the result. It's different from AI-assisted coding, where a person stays in control of the work and the AI only suggests.
How is agentic AI integrated into the software development lifecycle?
Agents step into each stage of the lifecycle you already have, drafting specs in planning, writing changes in building, generating tests, flagging risk in review, shipping and watching rollouts, and triaging alerts in operations. People stay on the expensive decisions: sharpening intent, approving merges, and deciding what ships. At scale, integration also means a control plane that gives every agent an identity, grounded context, scoped permissions, and an audit trail.
Is an agentic SDLC actually worth it, and what are the downsides?
The upside is concrete: more changes shipped, shorter lead times, and far less toil. The catch is that it only pays off if you govern it. Without the control plane, the same speed that helps you also helps a bad change reach production faster, costs climb with no clear return, and no one can say which agent did what. An agentic SDLC is worth it when you treat the infrastructure around the agents as the real project. It becomes a liability when you treat the agents as the whole thing.
Will AI agents replace software developers?
Not in the way the headline suggests. The agentic SDLC moves engineers from writing most of the code to setting intent, reviewing agent output, and owning the decisions agents shouldn't make alone. Judgment, design, and governance get more valuable, while typing gets less so. The hardest parts of building software were never the typing, and those parts still need a person.
What is a multi-agent software development workflow?
It's a workflow where several specialized agents each handle a part of a task and hand off to each other: one plans, one codes, one reviews, one operates, instead of one agent doing everything. It moves faster, and it raises the stakes on orchestration, because more agents means more handoffs, more permissions to scope, and more actions to keep a record of. Without shared infrastructure to trace the chain, a multi-agent workflow is where agentic technical debt piles up fastest.
What is an agentic SDLC platform, and what does it need to do?
An agentic SDLC platform is the control plane agents run on across the lifecycle. At a minimum it has to give every agent and tool an identity, ground their decisions in a live context lake, scope what each one is allowed to touch, check every action against your standards as it happens, and keep an audit trail you can question later. Without those, you can run agents, but you can't run them at scale without losing control.


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone




