Catalog Discovery: build a reliable software catalog with Port AI
We just launched Catalog Discovery. It cuts catalog-building time from weeks to minutes by analyzing your SDLC ecosystem and surfacing the entities and relationships teams usually map by hand. A complete, accurate catalog is the system of record for any human or AI that needs to act on your system. Catalog Discovery brings the catalog to that level from day one.


What breaks when the catalog is incomplete
Building a software catalog sounds easy until your data model pulls information from a bunch of systems and there’s no single source of truth. We built Catalog Discovery to fix that.
Imagine a service represented by a GitHub repo and a PagerDuty service. If the code lives in a monorepo, a repo like company/monorepo where the payments service sits under services/payments folder, the repo name gives no clue about the boundaries of the service. You’d have to inspect folder structure or the README to know what the repo actually contains. That’s exactly the kind of case where simple mapping rules fail and where Port’s Catalog Discovery pulls the signals together better.
Each tool holds a piece of the picture, but none of them tell you how all the pieces fit together. These gaps have real-world implications. When an on-call engineer wakes up at 3am, missing or wrong relationships make it much harder to trace the root cause and see which services are impacted - and that directly increases the time it takes to mitigate the incident.
This feature was driven by customer demand - originally submitted as our community feature request. We built this to address that traction. We see Catalog Discovery as a core part of the onboarding experience, where environment builders start with a usable catalog instead of a blank slate.. Over time, we plan to extend Catalog Discovery so catalogs stay accurate as systems change, without teams having to constantly re-audit their data.
Meet Catalog Discovery: scan your tools, then approve what gets merged
Catalog Discovery analyzes your data models and their relationships, then suggests missing entities or fills in missing details for existing ones. Review, edit, and approve each suggestion before it’s merged into your catalog, so you keep full control over your data. This gives teams a practical starting point, exposes the gaps immediately, and removes one of the biggest blockers to getting a working catalog into everyone’s hands.
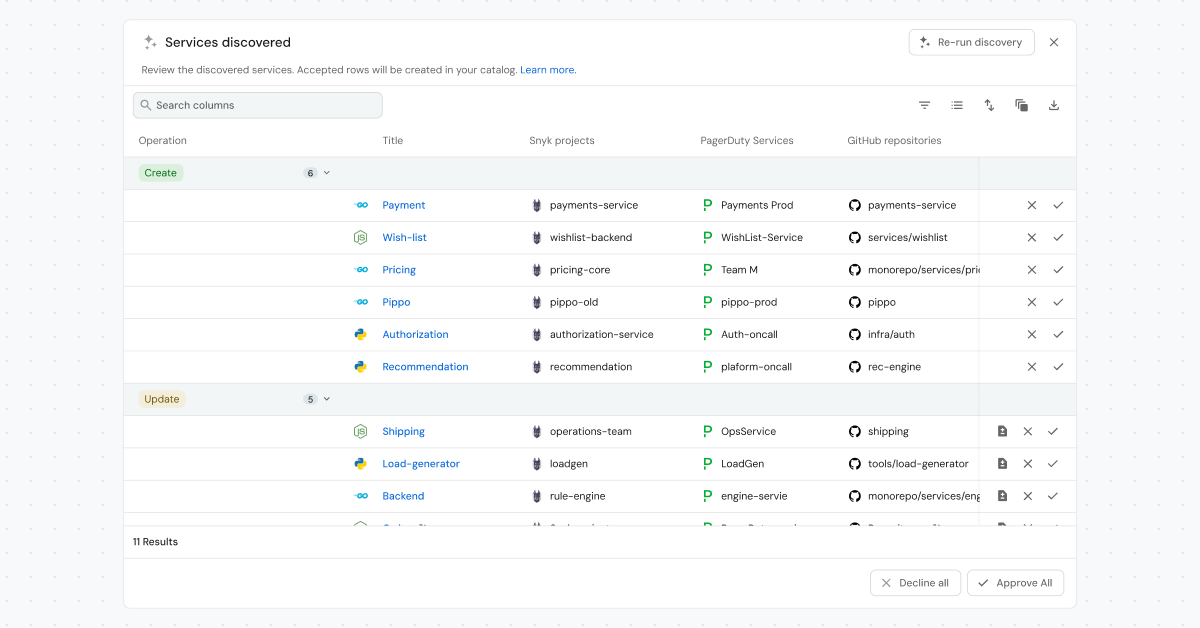
What reliable system context unlocks for AI and automation
With a trusted catalog in place, automation can work with real system context instead of guesses. Agents can identify the right owner, locate the correct repository, understand dependencies, and choose where changes are safe to apply.
This is what turns AI from a suggestion engine into something that can take real action like opening precise pull requests, routing work to the right team, or managing infrastructure changes, while keeping humans in control.
So what actually changes for teams?
- Starting from a usable catalog: Environment builders start with a usable catalog instead of a blank slate. That means access rules, ownership, and dashboards can be set up immediately, without waiting for every service to be perfectly mapped.
- Easier ongoing maintenance: Catalog Discovery isn’t a one-time setup. Platform owners can rerun discovery when systems change and review suggested updates instead of hunting for broken links or outdated relationships. Keeping the catalog accurate becomes a lightweight, repeatable task rather than a recurring cleanup project.
How to run Catalog Discovery in few steps
- Open a blueprint page - e.g. Service
- Click Catalog Discovery
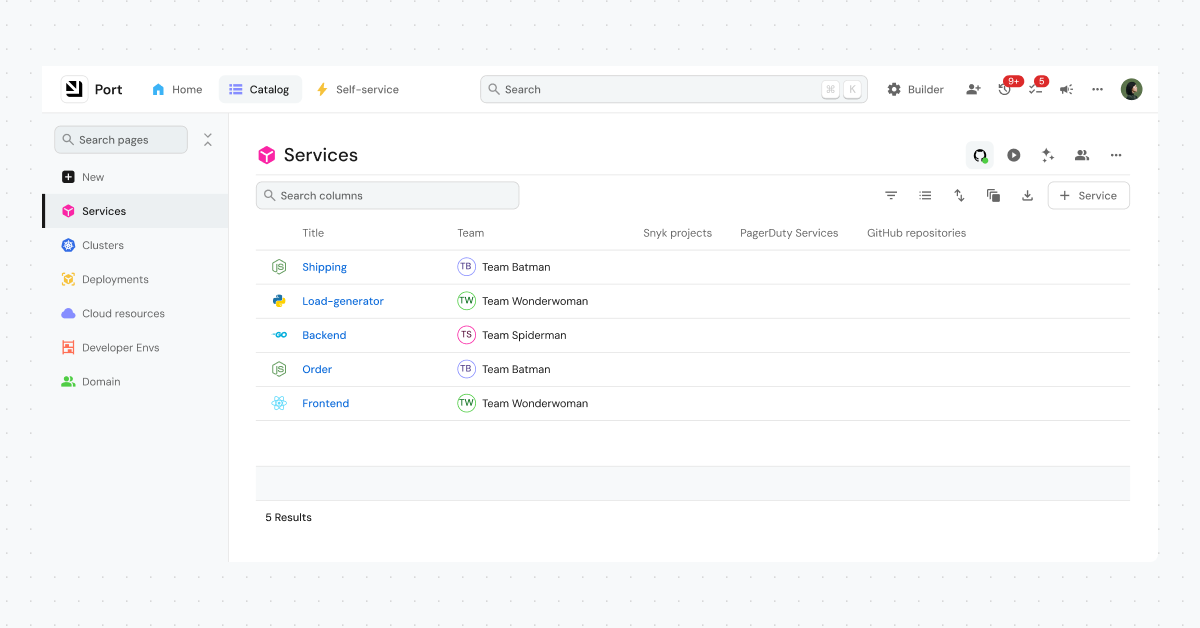
- Tell Port what “a service” looks like in your org
Configure discovery to define what an entity means in your organization. This gives the AI the context it needs to find the right signals across your tools.
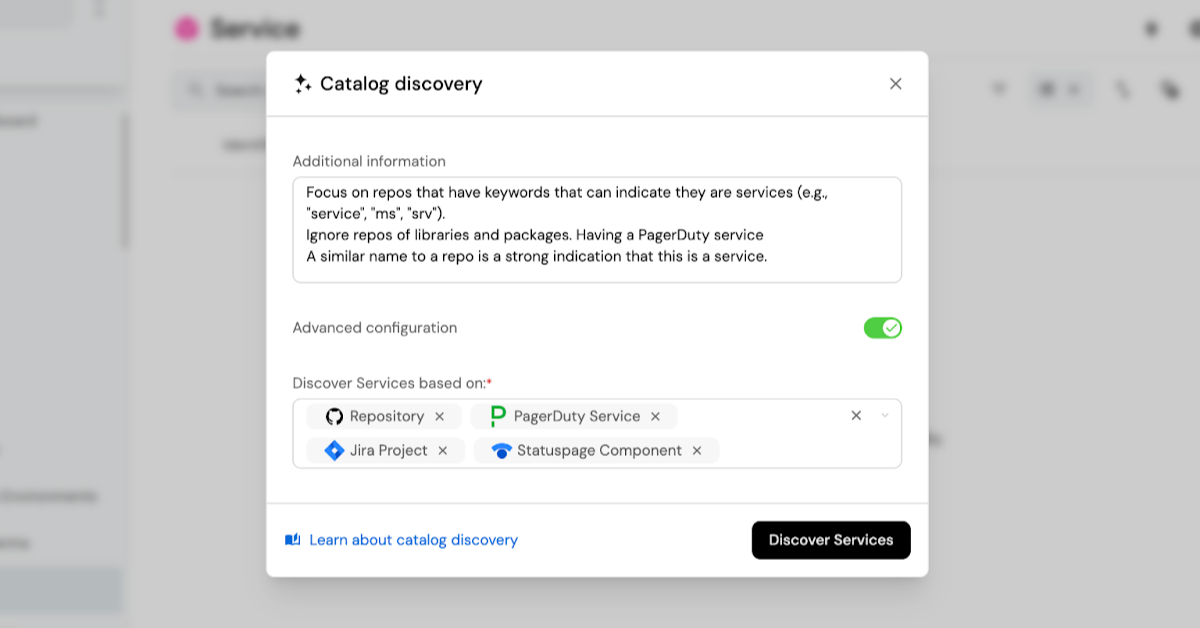
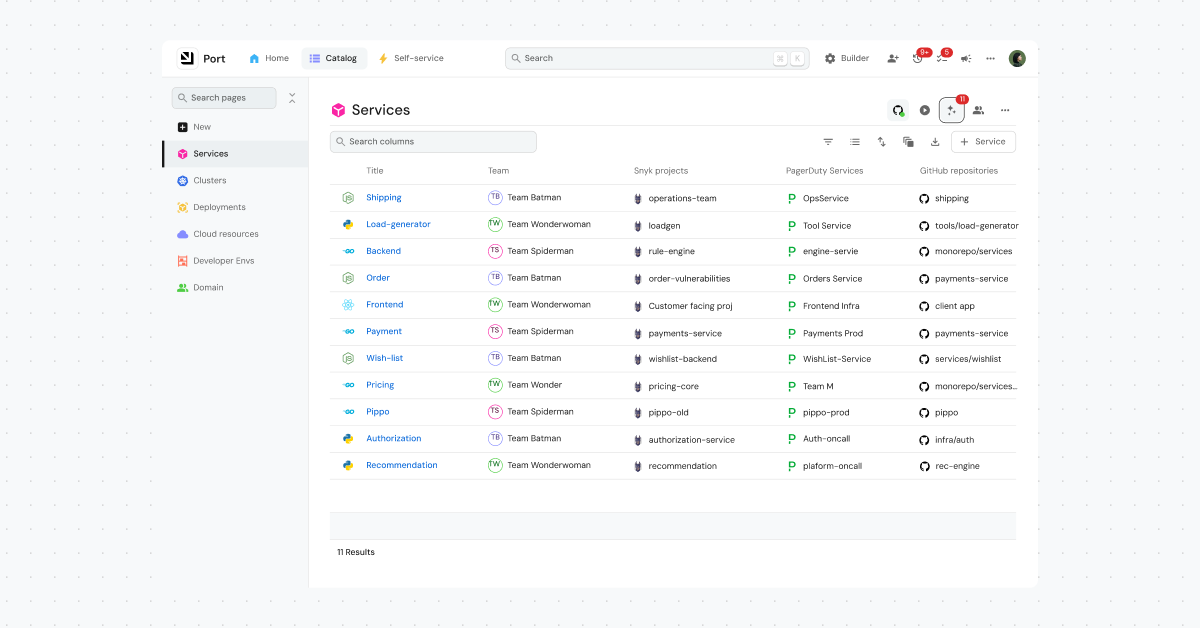
- Review suggested changes
- Approve or discard
Under the hood: three LLM stages that turn messy signals into a clean map
This feature uses a sophisticated multi-stage LLM workflow to automatically discover and map relationships between your software catalog entities. Here’s what happens behind the scenes when you start a discovery run:

- The blueprint detective - Which data sources should I even look at?
The first LLM call acts like a detective, analyzing your entire data model to figure out which blueprints (entity types) are most relevant for discovery. But here’s the clever part: it doesn’t just pick blueprints randomly, but:
- Examines upstream blueprints (entities that point to your target) and downstream blueprints (entities your target points to)
- Samples actual entities from each blueprint to understand what data really looks like (not just the schema!)
- Provides reasoning like: “Repository name and URL may contain the service name, and file_structure helps identify services in monorepos”
Fun fact: The system explicitly excludes noisy property formats like date-time, yaml, timer to avoid polluting context!
- Smart filtering - Fetch only the entities that matter
Before fetching thousands of entities, a second LLM call generates intelligent search queries for each relevant blueprint. The AI might decide: “For repositories, filter where language = ‘python’ and sort by updatedAt descending to get the most active ones first”
- The entity matchmaker - Connect the dots
The final (and most powerful) LLM call receives all the filtered context and outputs discovered entities with their relationships. The AI follows strict rules:
- Only use real identifiers from your existing entities (no hallucinated IDs)
- Distinguishes between “create” (new entities) and “update” (enriching existing ones)
- For updates: never removes existing relations, only adds new discoveries.
Have a look around
Start with an entity type that pulls data from multiple tools - like services linked to repos, on-call, and deployments - and run Catalog Discovery there. You’ll see missing links and details surface in minutes.
If you want to influence what we build next, submit or upvote ideas on our public roadmap.


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone




