Harmonize your domain for AI-powered platform engineering
Platform engineering must now include and account for AI needs. Learn how to treat them like equal users of your platform in this post.

Platform engineering has always been about empowering developers, but the term “developer” is getting a bit restrictive now that AI has been introduced. Really, it could be anyone using your portal now: SREs, PMs, and of course AI agents, are all totally legitimate platform users!
As a result, the definition — and scope — of platform engineering has to expand. We need to empower all platform users by offering them a harmonized platform domain model with self-service actions that provide clear golden paths for accomplishing tasks.
In this post, we’ll discuss why a harmonized domain enables better platform engineering — for humans and AI. Port’s remote MCP servers can offer you more AI orchestration benefits than external MCP servers by demonstrating its ability to navigate your domain and produce more efficient output.
How platform engineering needs to change
One of the important platform engineering strategies is harmonizing your platform domain model. This means more than just aggregating data from different sources (like your Git repos, K8s clusters/deployments, incident management tools).
In practice, a unified model for platform engineering accounts for the entirety of your SDLC and makes it iterable via a platform-as-a-product approach. This gives your teams more room to adapt and evolve functionality to address new challenges.
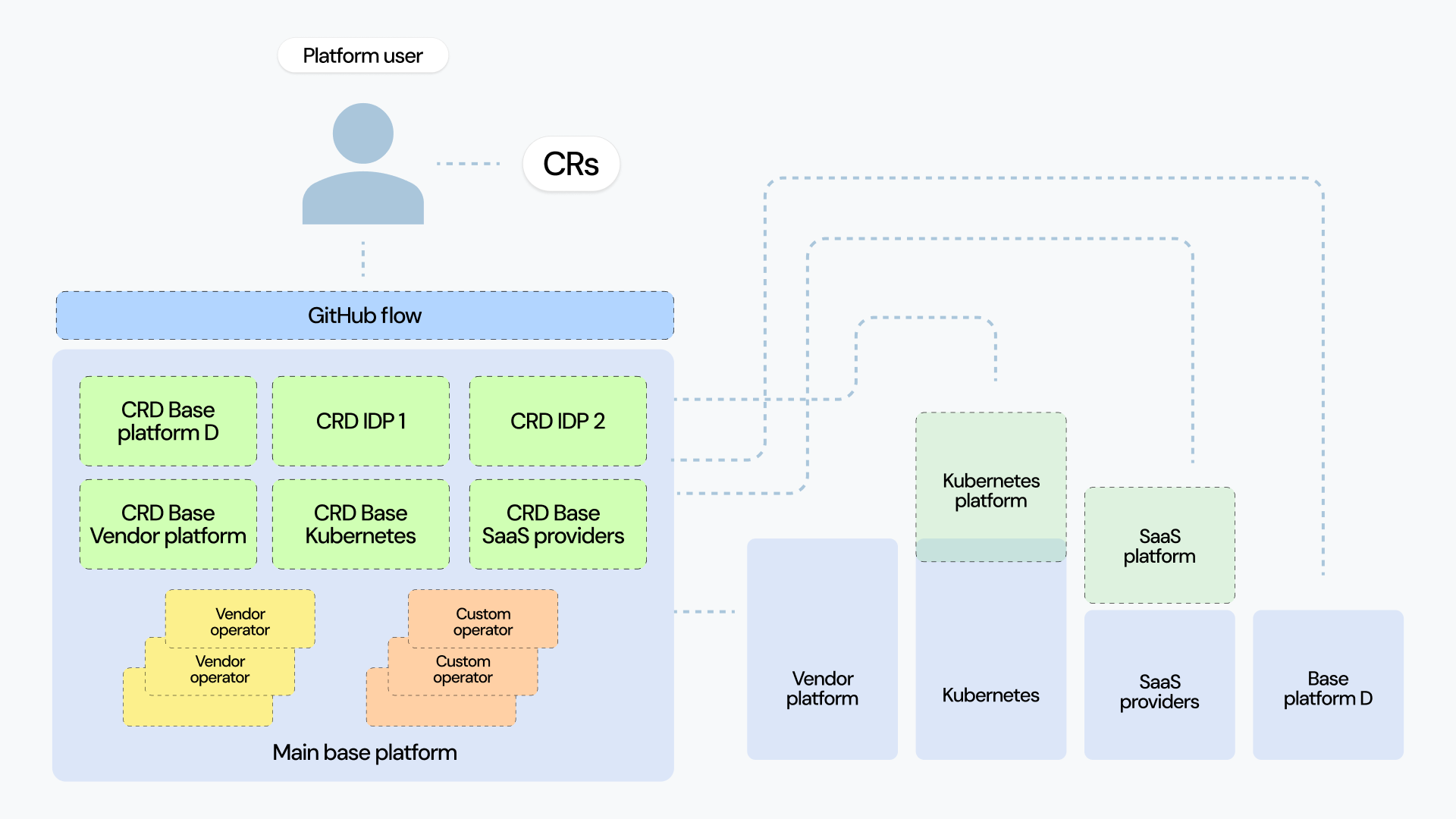
If you haven’t organized your domain, you will most likely end up with several platforms. This can be a mix of homemade portals or platforms, vendor platforms, SaaS providers, and base platforms like Kubernetes:

This completely negates the central goal of platform engineering: to give devs simplicity. Your devs, SREs, and managers will still have to switch between dozens of tabs to deal with simple flows, like releasing bug fixes or testing new features in QA environments, except instead of searching within individual tools you’ll have to switch between platforms. So how can we solve this?
Define your domain using the operator pattern
Nowadays, almost all of the cloud service vendors ship an operator; you can browse them using the Operator Hub. Operators work on top of custom resource definitions (CRDs) for Kubernetes environments, which we’ll focus on creating below.
Defining all of your resources and organizing them in specific Kubernetes clusters makes it easier to:
- Identify available resources
- Map relationships and dependencies between services
- Programmatically reference certain resources when prompting AI, and call them when needed
Custom controllers, which are just pods that can act on any custom resource, can then perform tasks inside your clusters, like generating config maps or deployments. It can also call an external API or put a record on a Kafka topic — you decide, you can do what you want!
But the most important benefit of this Kubernetes setup is leveraging the operator pattern, where we combine custom resources and controllers to define machine behavior.
The Kubernetes documentation defines the aim of the operator pattern as such:
The operator pattern aims to capture the key aim of a human operator who is managing a service or set of services. Human operators who look after specific applications and services have deep knowledge of how the system ought to behave, how to deploy it, and how to react if there are problems.
When you use the operator pattern as intended, you can automate things that would have previously required a service ticket, a human operator picking it up, and the operator resolving the ticket.
Even if you are using multiple cloud services, like a storage service and a streaming service, you can consolidate them into custom resources. Your developers and SREs can either apply a CR, or take a GitOps approach and commit a CR to a repository. From there, a GitOps tool like ArgoCD will make sure to apply that resource to your base platform.
A harmonized platform
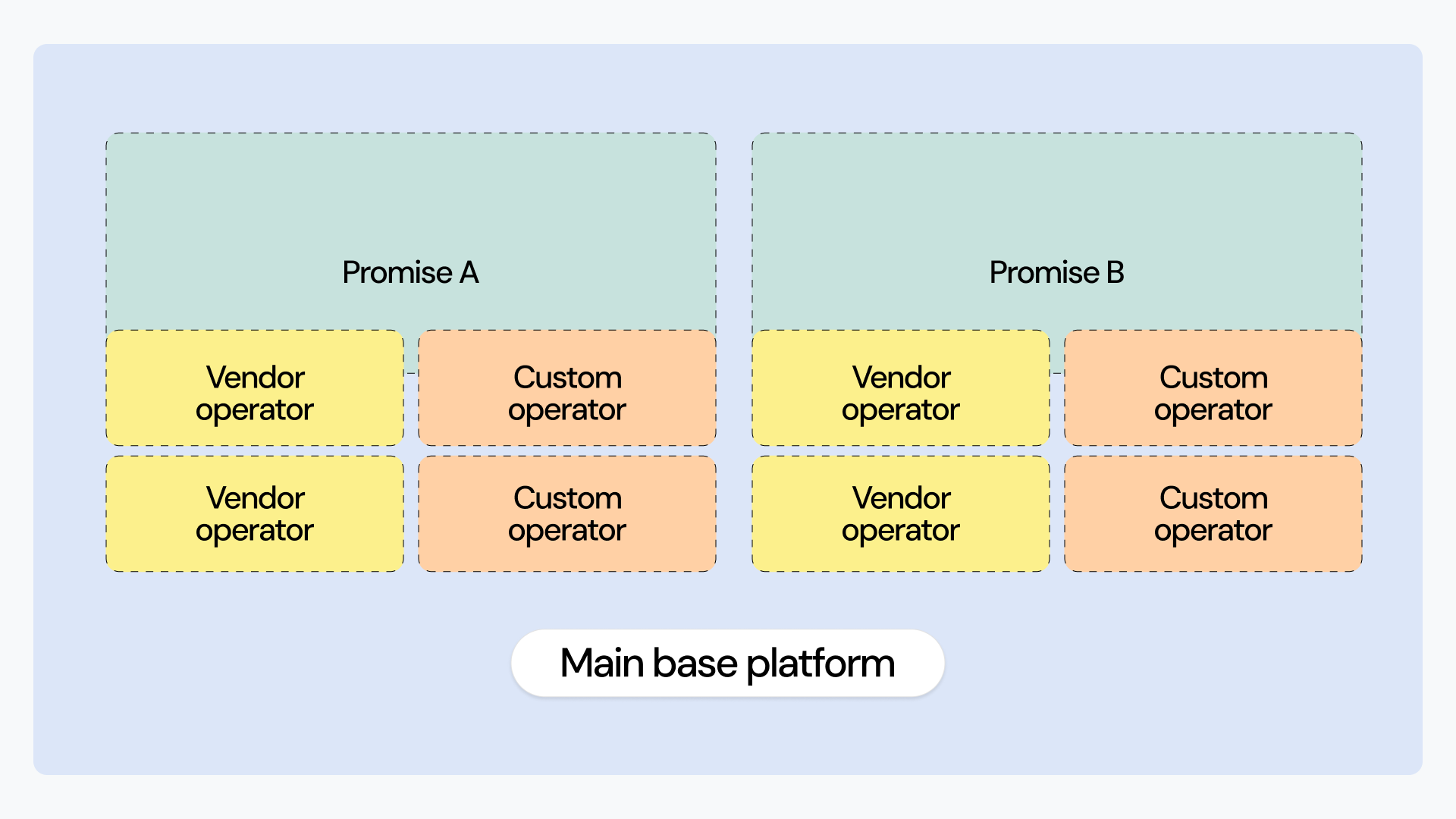
In taking the operator pattern approach, you end up consuming a set of vendors’ operators but also building, maintaining, and using your own custom operators. In an ideal situation, you should end up with something like this:
Even still, you have to be aware of falling into one of these traps without proper governance:
- Exposing too much of the API: By default, all operators (yours and those you consume from third parties) expose the entire API surface to your platform users. Consider what is essential for users to know, what isn’t, and what can be constrained by offering default values, with an emphasis on making the operator as useful and valuable as possible.
- Having too many operators: This one’s simple: if you give people too many options, they’ll be overwhelmed!
{{cta_1}}
Dealing with operator sprawl
At some point, you may end up with too many operators across your custom ones and those from different vendors. This poses the risk of overwhelming your devs with too many self-service offerings.
There are three different strategies we suggest taking to control or consolidate your operators:
1. Write a higher-order operator to trigger one or more lower-level operators
This option might sound like a joke — can writing even more operators solve a problem like this? — but it works. In some use cases, higher-order operators can streamline your CRD and map the original values of the vendor’s custom resource to your own CR.
Using this method, however, adds a new piece of software into your platform that will need to be maintained and upgraded along with the rest of your SDLC.
2. Compose your operators
I already mentioned the concept of creating a facade for your operators. The open source framework Kratix exists exactly for this purpose. It introduces the concept of a Promise to operators, which is like a more powerful CRD: you can still define your API, but you can also add dependencies like other CRDs and pipelines, which can basically transform your Promise API into one or more CRs.
3. Consolidate and streamline your platform domain with Port
If you’ve taken the above steps, you now have a much more consolidated platform domain. But you can still take this further.
Until now, we focused mainly on one persona: the developer. But your platform will be used by a wide spectrum of people working across your SDLC, each of whom will be dealing with other data flows that might not be covered by your existing custom resources, like real-time alerts outside of your domain:
You’ll need a component that understands CRDs and is, at the same time, completely agnostic of any data format. Better yet, adding a UI layer on top of that to streamline platform usage makes everything easier — and this is what Port’s remote MCP server can do for you.
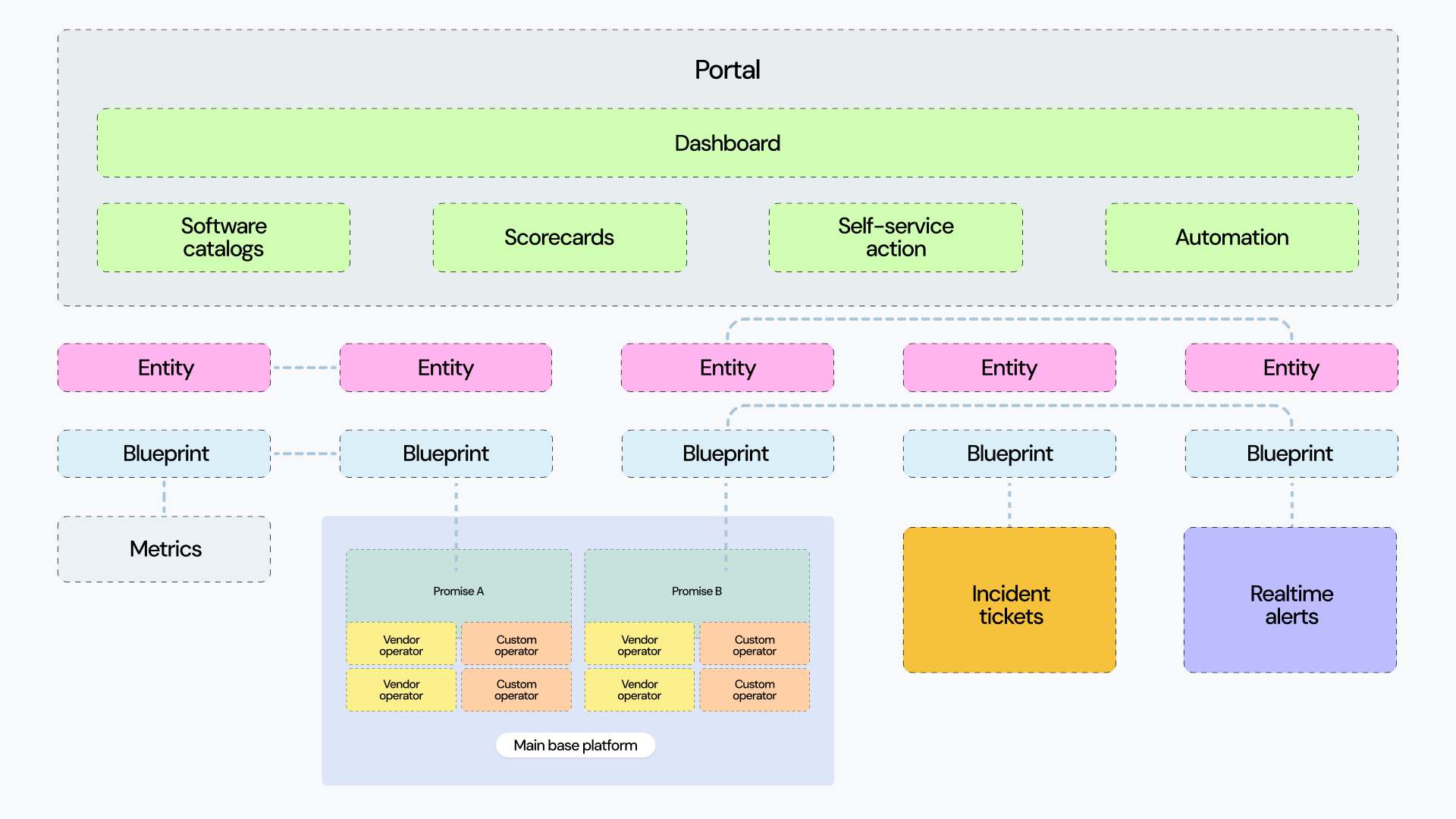
Even though an MCP server can’t understand the data it ingests, it can compile data from multiple different sources, including custom resources and specific JSON payloads, and map them to your data model, providing a unified experience to platform users. Blueprints in Port are very similar to CRDs, and you can even automatically create a blueprint from a CRD with Port!
From those blueprints, any approved portal user can create and consume new entities. The other huge advantage of the blueprints model is that it maps relationships between your entities, so you can link a Kubernetes custom resource and a PagerDuty record together for a comprehensive report.
How Port’s MCP enables platform engineering
With Port, you can easily leverage your harmonized platform domain model with AI, thanks to the flexible concept of Port blueprints and our MCP server. Together, you get the best platform possible, one where agentic AI runs through your SDLC like the blood of your platform.
Port’s MCP server is particularly well-suited to infusing AI into your platform. In the same way a human can self-serve resources using a portal or by pushing a custom resource to a Git repository and triggering a GitOps flow, you can configure your platform to expose self-service to AI tools.
The MCP server is how these tools are exposed, which means you have to make sure that all your self-service endpoints are exposed as MCP tools. In Port, you don’t have to worry about this — our MCP server will automatically expose each of your self-service actions as MCP tools, and it will even handle permissions.
Plus, it’s dynamic, which means that when your platform engineers add new self-service actions, they will automatically become available as tools AI can use via the MCP server. With this functionality, you can provide top-notch context data and write high-quality prompts for the LLMs your agents will call.
{{cta-demo-baner}}
Lean into platform engineering with Port
As more companies adopt AI (and see low returns on their investments), something you may want to consider is how well your developers can navigate your domain. If it’s too difficult to navigate for humans, it will also be that difficult for AI to produce clean, usable outputs. Organizing your information and making it easily consumable, readable, and placeable in the context of your engineering lifecycle is key to improving your AI usage and success.
Port can help you provide your unique domain context to your AI agents and human devs, in one place, and in real time, making it particularly easy to spin up agents that work alongside you, not against you.


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone




