How SPS Commerce built its internal developer portal
Hear from Travis Gosselin and Mark DeBeer about their experience building SPS Commerce's internal developer portal with Port.


Editor's note: This blog post was originally published at The New Stack on 1 July 2025.
Implementing an internal developer portal isn't just about choosing a tool; it's about reshaping how your engineering teams work and truly empowering them by committing to platform engineering best practices. If you're considering this path for your organization, learn from our experience at SPS Commerce. We operate the world’s largest retail network, connecting suppliers and retailers. We facilitate the exchanges of documents like purchase orders and invoices across the global supply chain. Over 50,000 customers use our network and our tech department is 700-strong.
A broken developer experience
In recent years, we experienced rapid growth as an organization and quickly accrued over 2,500 active items in our service catalog. With new developers and a suite of new tools to manage, our developer productivity engineering team had a new mandate to design better ways of working.
We quickly learned we’d need to better enable and empower our engineers: our teams were larger and spread out across projects, and closing the gaps between processes put strain on our developers.
A significant issue was tool sprawl — with over 20 development tools actively in use and plans to develop or adopt even more, we saw our developers spend countless hours each week wrangling a disjointed ecosystem.
To make matters worse, there was no central hub for seeing the complete context of an application. Imagine trying to understand 2,500 services without a way to display them in a single place! This lack of clarity, amplified by our rapid growth, led us to create disparate processes with spotty documentation across diverse tech stacks, which siloed work and isolated knowledge that should have been shared.
The search for a solution
Our first move toward finding a solution was to create an internal developer platform, which helped us abstract away some of the complexities our teams faced. But we quickly hit the platform’s limitations — it still took teams nearly two weeks to achieve their first “Hello, World!”
Despite the painful onboarding process, the platform taught us some important lessons about context and how we present it. Even if the details of our software development pipeline were clearly laid out, so many details exist that it was hard to distinguish between relevant and irrelevant data points.
Context needs to be obvious — if developers still have to piece together information from multiple sources, the benefit of the platform is lost. So, we asked ourselves, what context is essential? How can our platform deliver necessary context while offering developers a way to input their own insights?
Choosing an internal developer portal
We did our research and identified internal developer portals as a potential solution for providing the two-way context we needed. But the market offered several different options, each with its tradeoffs.
We took a hard look at what we learned from our platform initiative, what we still needed, and came up with some critical questions:
- Are we ready for a developer portal? Have we already taken some steps to centralize some of that context, perhaps with some type of tagging or categorization system? (Luckily, we had a head start on categorizing during our platform initiative.)
- Who will be on our implementation team? Are they front-end or back-end focused? What languages do they prefer? How many dedicated developers can be on this project, and for how long
- How custom is our toolchain? Is it so customized that it won't fit a rigid data model, or are we using standard tools, such as AWS and Azure pipelines, which most portals support out of the box? (Our toolchain proved to be standard.)
Based on our research, we found some portals offered more rigid data models, which appealed to our executive team because setup would be quick. But these portals were not able to adapt to all of our needs because of their rigidity — and that could hinder our long-term adoption and perhaps our ability to develop usable solutions for our team.
On the other end of the spectrum, we saw “unopinionated” developer portals that were completely customizable, but required a much more significant initial investment to set up than we could spend, as well as increased long-term maintenance, costs, and risks.
We knew that if we wanted to improve the quality of our developer experience, we needed to find a portal that could offer us some opinions to start with, like best practices to help us, while staying flexible in the long-term as our needs changed.
We did a thorough evaluation of everything on the market, from open source portal options, all the way to rigid portals. Ultimately, we chose Port for the following reasons:
- The flexibility of the data model and data ingestion
- The built-in interface designer, which offered an intuitive UI that made uploading and modeling data a breeze
- We could still design the portal using infrastructure as code, which let us adopt a routine release schedule across multiple environments
What a portal could do for us
One of the things we were most excited to figure out was how to structure our teams and develop an ownership model for our developer portal.
We embraced empathy-driven development: building the portal with engineers who understand the day-to-day needs of delivery teams. We adjusted our reporting lines to a matrix structure where teams report into different VP-level verticals but collaborate regularly.
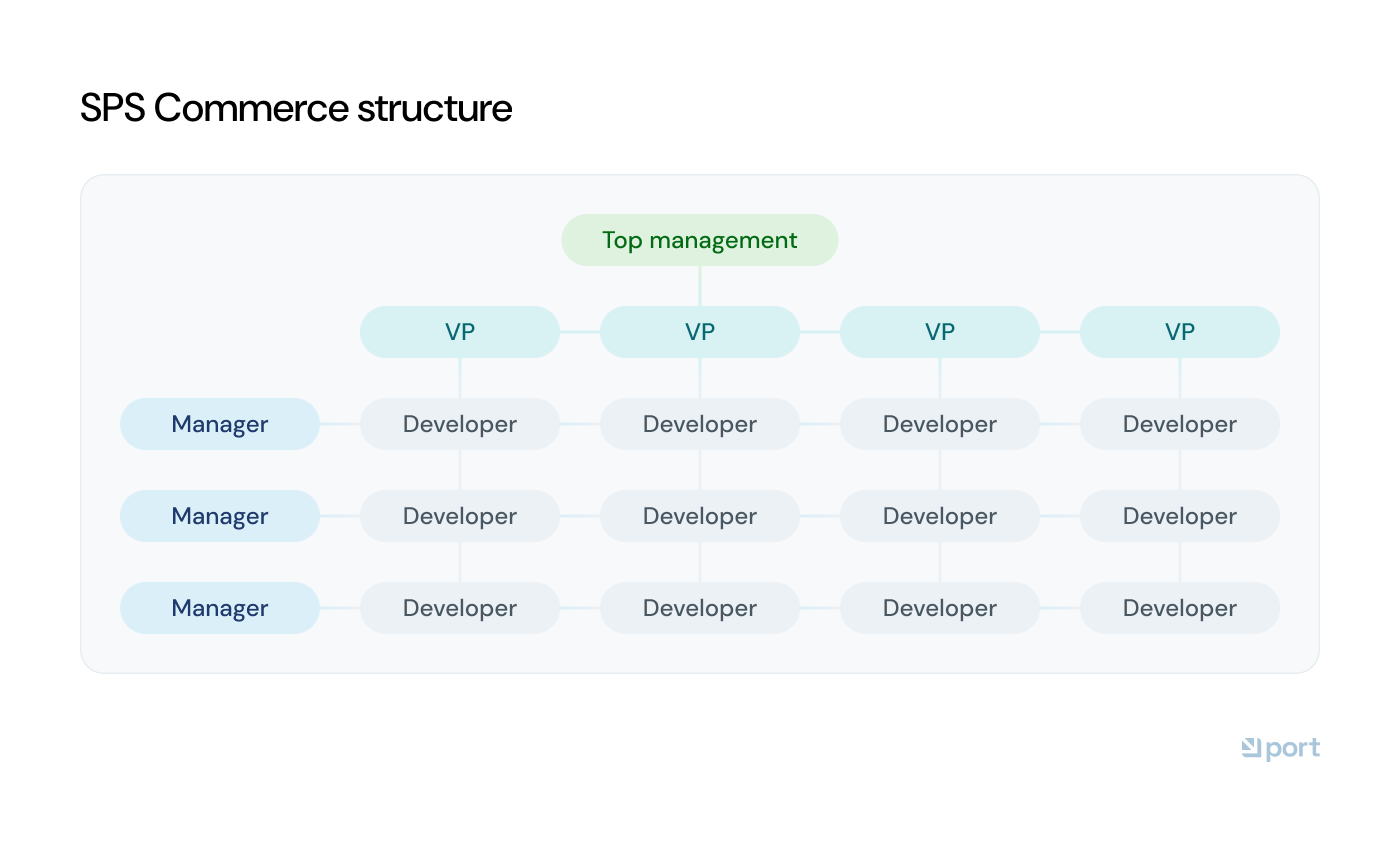
This approach gave us big benefits. Following a Team Topologies framework, our delivery teams act as stream-aligned teams, supported by platform teams like SRE, Platform and Cloud. Our developer productivity engineering team then serves as an enabling team, building empathy and insight into delivery needs.
We also clarified the team’s approach and goals: not to eliminate tool sprawl, but to manage it by connecting tools and context. Rather than replicating every UI, such as Kubernetes dashboards, we focused on deep-linking to them, with the right context built into the URLs.
Another big win we achieved early was improving our builder experience with infrastructure as code (IaC). This has helped our developer productivity team prototype data models, mappings, and actions quickly, allowing us to iterate fast and gather feedback in real time.
Once we were happy with a configuration, we codified it using IaC. This approach balanced speed and usability with control and consistency across experiences.
How we made our portal essential
Looking back, one of the most valuable decisions we made in building our developer portal was prioritizing the integration of our owned data sources into the portal first. This was important not only because they were foundational to our SDLC, but because our ops teams had already invested significant time into defining ownership and relationships among the resources.
We were able to borrow the context from what we’d already built and construct the portal’s primary use cases around it, using the shared ownership and security model we had already implemented. This familiarity and sense of continuity across approaches helped many embrace the portal with the consistency and accuracy that can often be left out of an organization's software catalog.
Encouraging adoption
We also needed to consider how to ensure our developer teams would adopt the portal. We felt that building a suite of high-quality self-service actions would be a great way to build on our foundational data sources.
We also wanted to make it easy to collaborate across teams, while giving developers fast, easy access to setup actions. The portal served as the technical foundation for our reusable action creation framework, as well as provided the business logic for each action.
To build our self-service actions, we used:
- Azure Pipelines for CI/CD, deployment, and running actions.
- Docker to package action logic in a portable, host-agnostic container.
- Pulumi for infrastructure as code, with plugins for Port and Azure Pipelines.
- TypeScript and Python to write business logic, depending on team preference. The common functionality we needed for all actions including getting and sending data to Port as well as error-handling and logging.
- Cookiecutter to generate action scaffolding and create pull requests automatically.
To tie it all up, we created a suite of documentation including “how-to” guides and videos, and getting started pages, as well as a Slack support channel to help those developing the portal.
Now, it only requires about five files to build, deploy, and run an action in the portal. The first four configure the action for deployment and runtime; the last contains the logic. Then, we took it one step further; the very first action we created in our developer portal was an action that would scaffold an action. This helped us encourage other teams to contribute, without placing all the burden on our small developer productivity engineering team.
Building scalable data models
We also put a lot of thought into data modeling. From the start, we wanted models that were scalable and maintainable. GitHub was our first data source, and since we treat Dependabot and Code Scanning alerts similarly, we created a unified vulnerability model. This made it easier to view and filter all vulnerabilities in one place and reduced duplication. Some properties, like severity, didn’t map perfectly — for example, Dependabot alerts lack a severity field — but we handled this with filters when needed.
For repositories, we built a generic code repo model with a type field to support platforms beyond GitHub, knowing we may one day acquire companies using tools like GitLab. This allowed us to integrate new sources by simply adding an integration and mapping, without defining a new model.
While this approach aligned with our goal of unifying related data, it raised questions in areas like pipelines, where GitHub Actions fit well into our pipeline models but conflicted with the concept of a pipeline project. We’re still figuring out the best solution.
Using generic models required more upfront thinking, but it helped us stay true to the developer portal’s purpose: bringing information together, not keeping it separate.
A more connected SDLC
Our internal developer portal, powered by Port, has delivered several tangible results for us:
- We finally have real-time visibility into platform migrations
One of our biggest wins has been giving teams a live view into major initiatives, like our CI/CD agent migration. Before, we’d hand out Jira tickets with static lists of services to update, and teams had no easy way to track progress. Now, every team can see exactly which services they still need to migrate, directly in the developer portal. We still have the Jira tickets, but they just link to the portal dashboard. And at the platform engineering level, we have our own dashboards to monitor the overall progress. - It’s made Kubernetes and Helm chart upgrades easier to manage
We’ve used the same approach for Helm chart upgrades. We need teams to stay current so we can move fast with Kubernetes versions, and the portal lets us surface which services are still tied to older charts that block upgrades. It’s made it much easier for teams to self-serve and stay up to date. - We’ve been able to consolidate our API catalog and add visibility
Port gave us enough flexibility that we could start consolidating our API design-first tooling. We’re pulling in OpenAPI and AsyncAPI specs, aligning them with the service catalog, and adding compliance and governance data on top. Now we have a centralized API catalog that also shows things like linting status, errors, and warnings across environments, all in one place. - We’ve opened up feature flag data to more people
Before, only a few people had access to feature decision provider data. Now we’ve imported that data into the portal so anyone who needs visibility — like managers, ops, or on-call — can see it. They don’t need extra licenses or special access anymore. And we’ve been able to create views to show which flags are active, inactive, or stale over time, which has really helped teams clean things up. - AI Agents aware of SDLC data: Using the portal to support AI agents gives us a unified and structured data model to provide them the context they need as well, and grant access to the agent via self-service action integrations. Now teams can ask direct questions in Slack, like “when did service abc go to production last?”
Building a developer portal isn’t something we’re ever truly “done” with. It’s an ongoing process of iteration, listening, and adapting. But so far, it’s already made a meaningful impact on how our teams work, and we’re excited to keep finding ways to make the developer experience at SPS better, more connected, and easier to navigate.


Get your survey template today
Download your survey template today


Free Roadmap planner for Platform Engineering teams
Set Clear Goals for Your Portal
Define Features and Milestones
Stay Aligned and Keep Moving Forward
Create your Roadmap


Free RFP template for Internal Developer Portal
Creating an RFP for an internal developer portal doesn’t have to be complex. Our template gives you a streamlined path to start strong and ensure you’re covering all the key details.
Get the RFP template


Leverage AI to generate optimized JQ commands
test them in real-time, and refine your approach instantly. This powerful tool lets you experiment, troubleshoot, and fine-tune your queries—taking your development workflow to the next level.
Explore now
Check out Port's pre-populated demo and see what it's all about.
No email required
LIVE WEBINAR, Aug 18, 2026:
Context-aware Vibe Coding for Platform Engineering
Move fast while staying in control
Build governed agentic workflows on one central platform.
To see it in action, check out this video on how you can create a workflow that generates Terraform using Port, or just have a quick look at our public demo.
.png)
Check out the 2025 State of Internal Developer Portals report
No email required
Minimize engineering chaos. Port serves as one central platform for all your needs.
Act on every part of your SDLC in Port.
Your team needs the right info at the right time. With Port's software catalog, they'll have it.
Learn more about Port's agentic engineering platform
Read the launch blog
Contact sales for a technical walkthrough of Port
Every team is different. Port lets you design a developer experience that truly fits your org.
As your org grows, so does complexity. Port scales your catalog, orchestration, and workflows seamlessly.
Port × n8n Boost AI Workflows with Context, Guardrails, and Control
Port Builders Session: A Single, Governed Interface for All MCP Servers
Book a demo right now to check out Port's developer portal yourself
Apply to join the Beta for Port's new Backstage plugin



n8n + Port templates you can use today
walkthrough of ready-to-use workflows you can clone
.png)



